I can already hear the rabble shouting, “Why would you use GoDaddy as your domain registrar?!” A fair question, but ...
Author: Joe
Selecting and Prioritizing Business ProjectsSelecting and Prioritizing Business Projects
First off, this post is not about how to manage your business projects but is instead about how to decide ...

Encrypting Existing S3 BucketsEncrypting Existing S3 Buckets
Utilizing encryption everywhere, particularly in cloud environments, is a solid idea that just makes good sense. AWS S3 makes it ...

macOS Big Sur Battery Percentage In the Menu BarmacOS Big Sur Battery Percentage In the Menu Bar
After upgrading to macOS Big Sur beta I noticed that the battery percentage disappeared from my menu bar. One would ...

I2C with the SiFive HiFive1 Rev BI2C with the SiFive HiFive1 Rev B
Hey kids! Today we’re going to take a look at the SiFive HiFive1 Rev B and Freedom Metal I2C API. ...
Exploring HiFive1 Rev B GPIOs with PlatformIOExploring HiFive1 Rev B GPIOs with PlatformIO
In our last post we looked at the GPIO pins of the SiFive HiFive1 Rev B board, and in this ...
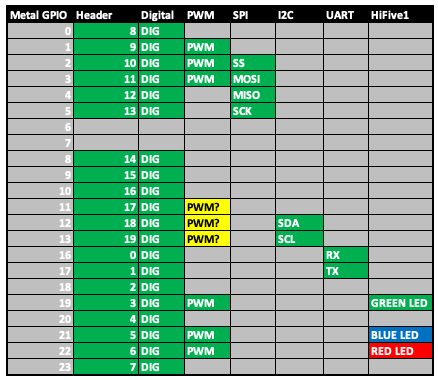
HiFive1 Rev B GPIO PinsHiFive1 Rev B GPIO Pins
Let’s make use of the HiFive1 Rev B schematics to map out the GPIO controller device pins. Of particular interest ...

An Introduction to the HiFive1 Rev B and RISC-VAn Introduction to the HiFive1 Rev B and RISC-V
Today I’d like to introduce you to a new development board, the HiFive1 Rev B. Equipped with a RISC-V Freedom ...

Working with ARM AssemblyWorking with ARM Assembly
Don’t ask me why I started looking at writing basic ARM assembly routines. Perhaps it’s for the thrill of it, ...
Seriously Good Coffee Doing Serious GoodSeriously Good Coffee Doing Serious Good
In the fall of 2018 my CEO and friend David Michel sat down next to me at our corporate Thanksgiving ...