Sigh. This post is related to no route to host. Have you noticed that Firefox, or perhaps Brave, can’t browse ...
macOS Sequoia No Route to HostmacOS Sequoia No Route to Host
macOS Sequoia has added a new (and dare I say, mildly annoying) Privacy & Security category for accessing your local ...

Installing Greenbone OpenVAS on Ubuntu 24.04Installing Greenbone OpenVAS on Ubuntu 24.04
Ubuntu 24.04 LTS, the “Noble Numbat”, has arrived, and I wanted to get Greenbone OpenVAS up and running on it. ...

Developing on a Mac – Python and Machine Learning – Part IDeveloping on a Mac – Python and Machine Learning – Part I
I wrote Part I of the Developing on a Mac series to provide a foundation upon which to build a ...
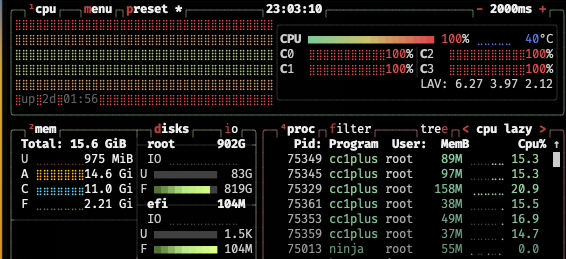
Compiling LLDB on the RISC-V HiFive UnmatchedCompiling LLDB on the RISC-V HiFive Unmatched
Different processors and instruction set architectures have always fascinated me. As a child of the late 70s and 80s I ...
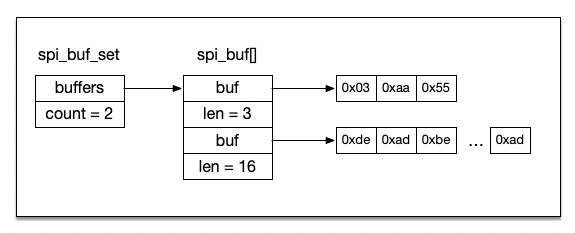
HiFive1 Rev B, Zephyr, and SPIHiFive1 Rev B, Zephyr, and SPI
A few years back I purchased a SiFive HiFive1 Rev B board to join in the RISC-V revolution. In this ...
The Case of the Unruly Chip Select SignalThe Case of the Unruly Chip Select Signal
Troubleshooting digital signals and protocols such as Serial Peripheral Interface (SPI) and Inter-Integrated Circuit (I2C) can be notoriously difficult. The ...
Using a HyperPixel 4.0 TFT Display on a Pi 3Using a HyperPixel 4.0 TFT Display on a Pi 3
You may have noticed that Raspberry Pi 4s are a bit hard to come by these days. The all-knowing Google ...
Developing on a Mac – Part III – NodeJSDeveloping on a Mac – Part III – NodeJS
I wrote Part I of this series to provide a foundation upon which to build a collection of minimal guides ...
Developing on a Mac – Part II – RailsDeveloping on a Mac – Part II – Rails
I wrote Part I of this series to provide a foundation upon which to build a collection of minimal guides ...